
It is nice to know how Google works and people should understand and just not panic when Google announces a new update.
Introduction
Search used to be about keywords. If you typed “cheap flights London to Paris”, Google looked for pages that contained those words in roughly the same order. But human language isn’t that simple. We use context, tone, and subtle shifts in meaning that keywords alone can’t capture.
That changed in 2019 when Google rolled out BERT — Bidirectional Encoder Representations from Transformers. Suddenly, the search engine had the power to understand language more like we do: not just word by word, but in full context.
Google updates after the “Markov era” of PageRank/click models.
The next major leap was RankBrain (2015) and then BERT (2019).
But in terms of impact: BERT was the big update everyone remembers as the turning point into deep contextual understanding.
Probabilistic modeling and SEO—BERT offers a bridge between statistical flow and semantic depth. It’s the kind of model that can help you optimize content not just for keyword density, but for meaningful relevance. Want to explore how BERT-style embeddings could be applied to your site’s content graph or user flow modeling?
🧠 What Makes BERT Different?
Bidirectional Context: Unlike older models that read text left-to-right or right-to-left, BERT reads in both directions simultaneously. This allows it to grasp the full context of a word based on its surroundings.
Transformer Architecture: BERT is built on the transformer model, which uses self-attention to weigh the importance of each word in a sentence relative to others. This is what gives it such nuanced understanding.
Masked Language Modeling (MLM): During training, BERT randomly masks 15% of words and learns to predict them using context. This forces the model to develop deep semantic awareness.
Next Sentence Prediction (NSP): BERT also learns relationships between sentences by predicting whether one sentence logically follows another. This helps with tasks like question answering and summarization.
Why It Changed the Game
- Contextual Embeddings: Unlike static word vectors (e.g., Word2Vec), BERT generates dynamic embeddings—the meaning of a word changes depending on its context.
- Fine-Tuning Friendly: Once pre-trained, BERT can be fine-tuned for specific tasks like sentiment analysis, named entity recognition, or search relevance with minimal additional data.
- Real-World Impact: BERT powers Google Search, improves chatbot comprehension, and enhances tools like voice assistants and document classifiers.
The Maths (light but meaningful)
1. Embeddings (vectors)
Every word is turned into a vector (a list of numbers).
-
E.g. “bank” might map to
[0.13, -0.72, 0.55, …]. -
Context matters: in “river bank” vs “bank loan”, BERT gives you different vectors for “bank”. That’s the magic.
2. Attention mechanism
The core operation:
Attention(Q,K,V)=softmax (QKTdk)V\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^T}{\sqrt{d_k}}\right)V
-
Q = query (the word we’re focusing on).
-
K = keys (all words in the sentence).
-
V = values (representations of those words).
-
The dot product QKTQK^T scores how much each word relates to another.
-
Softmax normalises these into probabilities.
-
Multiply by V = blend of word meanings, weighted by relevance.
So in “He went to the bank to deposit money”, the word “bank” will attend to “deposit” and “money” more strongly than to “river”.
3. Transformer layers
BERT stacks 12+ layers of these attention blocks, each refining the contextual representation.
-
After training, each word’s vector encodes very nuanced meaning.
-
This produces embeddings Google can use to match queries ↔ documents, even if the words don’t overlap exactly.
Why it mattered for Google Search
Before BERT, Google could misunderstand little words like “to”, “for”, “not”.
-
Example: “2019 brazil traveler to usa need a visa” — pre-BERT, Google missed the direction (Brazil → USA).
-
With BERT’s bidirectional context, it finally caught the true meaning.
Training (the clever bit)
BERT is trained with two simple tasks:
-
Masked Language Model (MLM)
-
Randomly mask words in a sentence (e.g. “I went to the [MASK] to deposit money”).
-
Model must guess the missing word using both sides of context.
-
Forces deep understanding of word relationships.
-
-
Next Sentence Prediction (NSP)
-
Show two sentences, ask if the second follows the first.
-
Helps with passage-level tasks (like understanding queries that span multiple sentences).
-
In SEO terms
-
Google uses BERT embeddings to match queries to content by meaning, not words.
-
That’s why “slough SEO company for small businesses” can match a page optimised for “SEO services in Slough helping local businesses grow” — even without exact keyword match.
⚡ In short:
-
Markov chains: probability flows.
-
BERT: vector spaces + attention maths.
-
It’s not just “keywords” anymore — it’s geometric closeness of meaning in high-dimensional space.
A simple worked example from our website right here:
-
Take a sentence from our SEO Home page (e.g. “Innovative SEO strategies boost rankings and traffic.”).
-
Show how BERT would represent the word “boost” differently depending on the surrounding words.
-
Then generate a small attention heatmap (toy version) to visualise how BERT focuses on “rankings” and “traffic” when interpreting “boost”.
Let’s create that attention example based on a sentence from our SEO page so it ties directly into our own content?
BERT Toy Attention Map for word: ‘boost’
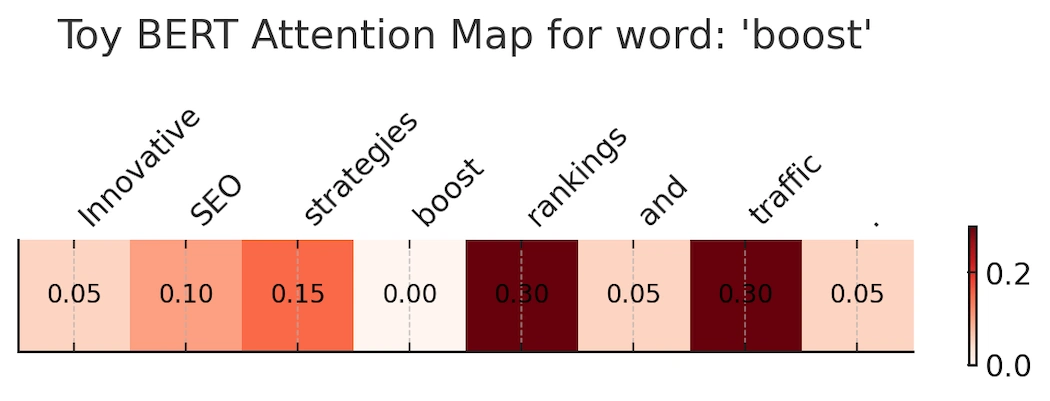
Here’s a toy BERT-style attention map for our sentence:
“Innovative SEO strategies boost rankings and traffic.”
-
The word “boost” looks around the sentence.
-
It places the strongest weight on “rankings” (0.30) and “traffic” (0.30).
-
Smaller weights go to “strategies” (0.15) and “SEO” (0.10).
-
Almost no attention goes to the period or “and.”
This mirrors how BERT actually works: it dynamically learns which nearby words matter most to a token’s meaning. That’s why Google can interpret “boost rankings” in a way that connects to SEO services without needing an exact keyword match.
Key point
BERT doesn’t have built-in grammar rules like “verbs are important”. Instead, it learns patterns statistically across billions of sentences. Verbs just happen to emerge as high-attention tokens because they carry meaning about relationships and intent, which Google needs to understand queries.
✅ So: BERT looks at all words equally at first, but in practice, verbs and key nouns often dominate the attention maps because they’re the backbone of meaning.
How BERT Understands Context
Take the sentence:
“Innovative SEO strategies boost rankings and traffic.”
BERT doesn’t just look at words in isolation. Instead, it creates an attention map that shows how much each word matters to the meaning of another.
In this case, when the model processes the word “boost”, it gives the highest attention weights to:
-
“rankings” (0.30)
-
“traffic” (0.30)
Smaller weights go to:
-
“strategies” (0.15)
-
“SEO” (0.10)
Almost no weight is given to filler words like “and” or punctuation.
Why this matters for SEO:
-
Older search models would see “boost” as just a word.
-
BERT, however, understands that “boost” relates most strongly to “rankings” and “traffic” in this sentence.
-
This means Google can connect your content to queries like “improving website rankings” or “increase web traffic with SEO” even if those exact phrases aren’t present.
👉 This shift from keywords → context is why content depth, natural phrasing, and semantic variety now matter more than keyword density.

Here’s another toy BERT-style attention map using our sentence:
“At TG Barker SEO, we specialize in delivering tailored search engine optimization strategies designed to elevate businesses in Slough and beyond.”
When the model processes “elevate”, it puts the strongest attention on:
-
“businesses” (0.25) → because what’s being elevated is businesses.
-
“tailored search engine optimization” (0.08 each) → the method of elevation.
-
Smaller weights go to “SEO”, “specialize”, and “strategies”.
Why it’s useful for this article:
-
Shows that BERT isn’t keyword matching “elevate” → “elevate” elsewhere.
-
Instead, it understands relationships (elevate → businesses via SEO strategies).
-
That’s why our content about “tailored SEO” will still connect to searches like “helping Slough businesses grow with SEO.”
How BERT Understands Context in Real Sentences
One of the biggest shifts BERT introduced was the ability to look at words in relation to their neighbours. Instead of treating each term as a standalone signal, it creates an attention map that shows which words matter most to the meaning of another.
Example 1: Boosting Rankings and Traffic
Sentence: “Innovative SEO strategies boost rankings and traffic.”
-
When BERT processes the word “boost”, it directs the strongest attention to:
-
“rankings” (0.30)
-
“traffic” (0.30)
-
-
Smaller weights go to “strategies” and “SEO”.
-
Almost no attention is given to filler words like “and”.
👉 This shows how BERT learns that “boost” in this context means “improve rankings and traffic,” not just “make bigger.”
Example 2: Elevating Businesses with SEO
Sentence: “At TG Barker SEO, we specialize in delivering tailored search engine optimization strategies designed to elevate businesses in Slough and beyond.”
-
When the model looks at “elevate”, its strongest link is to:
-
“businesses” (0.25)
-
-
It also attends to “tailored search engine optimization” (0.08 each) and “strategies”.
-
The word is clearly tied to the goal (helping businesses grow) and the method (SEO strategies).
👉 Instead of just seeing “elevate” as a generic term, BERT captures the intent: “help businesses grow through SEO.”
Why This Matters for SEO
Older search models relied on keywords alone. If we didn’t write “increase web traffic” exactly, we might not rank for it.
-
With BERT, Google recognises that “boost traffic”, “grow visitors”, and “elevate business visibility” all belong in the same semantic space.
-
That means high-quality, natural writing — not keyword stuffing — is the best way to get discovered.
⚡ In practice: If our content clearly explains what we do and who it helps, BERT will bridge the language gap between your page and the many different ways people search.
Practical Takeaways for Content Creators
-
Write naturally — don’t stuff keywords.
-
Cover topics in depth — context matters more than exact phrasing.
-
Use clear verbs, nouns, and descriptive qualifiers — they help BERT anchor meaning.
-
Structure content with subheadings and logical flow — easier for humans and algorithms alike.
Beyond BERT: What Came Next
-
MUM (2021): Multimodal, multilingual, multitask transformer 1,000× stronger than BERT.
-
Gemini & AI Overviews (2023–2025): Generative AI directly answering questions in SERPs.
BERT was the gateway — the moment Google fully embraced transformer-based AI. Everything since builds on this foundation.
Conclusion
BERT taught Google to read more like us. It doesn’t just scan for keywords — it understands context, relationships, and intent. For SEO, this means a shift: from optimising for algorithms to writing genuinely helpful, natural content.
If PageRank was about authority, BERT is about understanding. Together, they shape how every search result you see today is chosen.
Get Your Magic Juice 20% Boost
Want a quick win that shows you exactly where you’re losing rankings?
My Magic Juice Audit is built for businesses that want fast improvements without long contracts.
Guaranteed 20% Magic Juice Improvement
If your site doesn’t reach at least a 20% improvement in visibility, rankings, or overall site strength within 30 days of applying your personalised action plan, we don’t walk away — we keep working with you at no extra cost until you hit it.
You get results, or you get ongoing support for free. Simple as that.
This is a once-off private and confidential audit for only £375.00.
Your audit shows you exactly what’s holding your site back, exactly what needs fixing, and exactly how to unlock the growth your website should already be getting.
You can choose for us to implement the changes (optional additional fee), or simply give our clear optimisation instructions to your existing developer or SEO agency. Either way, your authority gets redirected to the pages that should be ranking — fast.
You’ll receive the full Magic Juice audit as explained here, delivered within 48 hours.
Start Your 20% SEO Improvement. | Gordon’s Direct contact:
Click here to contact me and get started.